
现状
现在浏览器css匹配核心算法的规则都是是以 right-to-left 方式匹配节点的。
如.root .sub span {…},浏览器渲染方式是 span -> .sub -> .root
它的读取顺序变成:先找到所有的span,沿着span的父元素查找.sub,再找.root,中途找到了符合匹配规则的节点就加入结果集;如果直到根元素html都没有匹配,则不再遍历这条路径,从下一个span开始重复这个过程。
举例
如果整个html只有一个span标签,那 right-to-left 方式的确是最快的,但是往往大部分网页都不只一个span标签,多个span标签将会有很多无效的匹配,那这时是不是 left-to-right 会更好一点。
案例:
<html>
<div class="root">
<div class="sub"><span>1</span></div>
</div>
<div>
<div><span>2</span></div>
</div>
<div>
<span>3</span>
</div>
<span>4</span>
</html>
.root .sub span {}
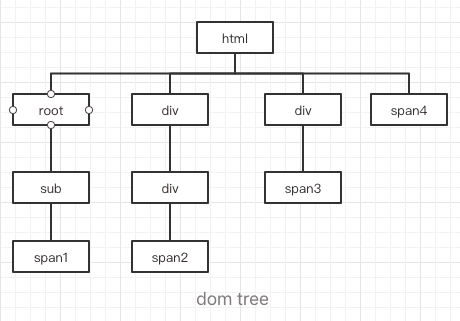
` right-to-left 解析
先找到所有的最右节点 span,有4个,对于每一个 span,向上寻找节点发现不是.sub,在查找上上节点,直到找到html,发现没有符合的。再从下一个span开始重复这个过程。
上面情况有4个span至少有4个分支的往上遍历。假如有 1000 个 不在.sub中的span`,就有 1000 次的分支遍历,而符合条件的只有1个,会损失很多性能。
` left-to-right 解析
从 .root 开始,遍历所有子节点,如果没有找到.sub,回溯到上个节点接着遍历,直到找到.sub,再遍历.sub下的子节点找到span结束。
上面情况1次就能找到符合条件的span`。
上面案例明显 left-to-right 比 right-to-left 解析效率更高。
当然也有情况是,如果.root下面有很多复杂子节点,需要遍历与回溯很多次,而.root外的span不多,则 right-to-left 解析效率更高。
提案
大部分书写习惯是不想每个html标签都加class name,可以用不同html标签选择出来的。如下所示:
<div>
<div id="sub">
<span>1</span><label>2</label><div>3</div>
</div>
... <!-- 里面有很多span,label,div标签 -->
</div>
#sub span{}
#sub label{}
#sub>div{}
先找到#sub再找html标签的话,css解析效率会高些。
那么 left-to-right 比 right-to-left 解析效率高。
所以提案如下:
假设最后一个css元素是html标签,而父元素有ID或Class选择器时,则选择器解析从左往右的,其他情况还是从右往左。
Ps:这里本妹子的一个想法,欢迎各位小伙伴们一起讨论,如果大部分都觉得有道理的话,我想试着向
w3c组织提出建议需求。
Happy coding .. :)